Only 4 Components, (m)eine Einschätzung
Vielleicht haben Sie sich bei einigen Themen auch schon gefragt: Warum muss das immer so komplex, vielleicht sogar kompliziert sein?
Beim Aufbau der a3 = Advanced Analytics Appliance gehen wir auch an einigen Stellen etwas ins Details. Und vielleicht könnte das auch bereits komplex oder auch kompliziert auf Sie wirken oder sogar sein. Wobei kompliziert natürlich relativ ist.
Bei der Konzeption einer Datenanalyse-Plattform, die Sie gegebenenfalls soeben aufbauen möchte, wäre zu Beginn Komplexität oder Kompliziertheit wenig hilfreich.
Um das zu umgehen, konzentrieren wir uns zu Beginn auf die folgenden 4 Komponenten: Storage, Compute, Analytics, Access
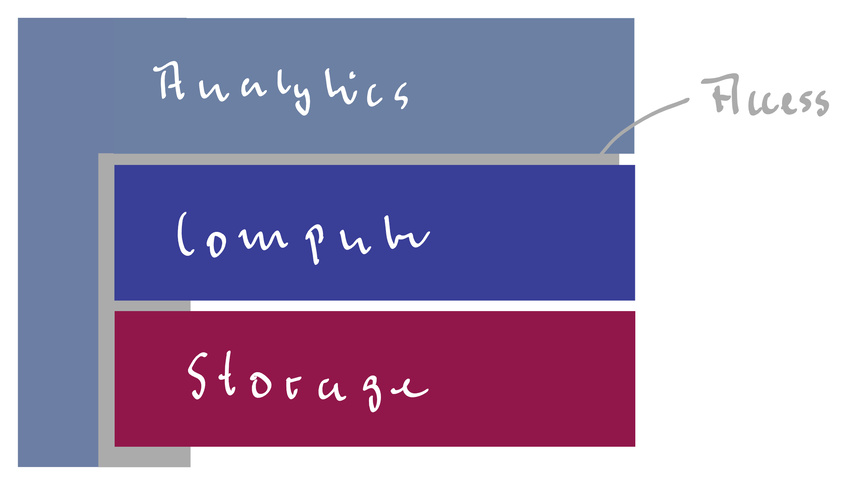
Ergänzend müssen wir uns vorab folgende Fragen beantworten:
- Wozu benötige ich diese aufzubauende Analyseumgebung?
- Welche Daten und Arten von Daten habe ich?
- Wann müssen die Daten verfügbar sein?
- Wer soll Zugriff auf die Umgebung und die Daten haben?
- Wo möchte ich die Daten speichern und die Analysen ausführen?
Kommen wir aber nun zu den bereits genannten 4 Komponenten.
Storage
Wir starten beim Wo und beginnen mit dem Wo kommt das eigentlich alles her? In vielen Unternehmen oder Institutionen wird noch immer, beispielsweise, der Wunsch nach einem Hadoop-Cluster oder dem Auto-Scaling einer Anwendung bei einem Hyperscaler geäußert, da die Interessierten entweder über dessen Leistungsfähigkeit viel gelesen oder von erfolgreicher Integration bei einem Tech-Unternehmen aus den USA gehört haben. Und genau aus diesem Umfeld, den Tech-Unternehmen (zum großen Teil aus dem Silicon Valley) wie Facebook, Google, Amazon, AirBnB, Netflix oder Yahoo kommen diese Technologien. Wenn wir uns nun die Geschäftsfelder dieser Unternehmen anschauen und in welchem Bereich eine solche Technologie entstanden ist oder eingesetzt wird, so sehen wir sehr häufig, vielleicht sogar meistens, nachgelagerte (dispositive) Systeme für Analysen von Kundendaten oder Kundenverhalten oder zur Vorhersage von Ereignissen basierend auf Daten von Webservern.
Gehören Sie auch zu dieser Gruppe von Unternehmen? Oder möchten Sie etwas anderes erreichen? Ist Ihnen wichtig neben strukturierten Daten (z.B. CSV Dateien, Daten aus Ihrem Stamm- oder Transaktionsdatensystemen) auch unstrukturierte Daten (z.B. von den Sensoren Ihrer Industrieumgebung) zu speichern. Und den Zugriff sowohl auf historische Daten, wie auch auf Daten, die sehr zeitnah verfügbar sein müssen, anzubieten.
Das Hadoop-Ökosystem bietet hier neben dem Hadoop Distributed FileSystem (HDFS) auf einem Hadoop-Cluster auch weitere Pakete, die jeweils einzelne Aspekte abdecken. Am Markt haben sich aber auch andere verteile Dateisysteme, wie beispielsweise Minio oder GlusterFS, etabliert, die mit sehr viel weniger Aufwand eine vergleichbare Speicherung und Bereitstellung anbieten. Und zur Speicherung von Nachrichten, wie die genannten Sensordaten, gibt es schon länger Systeme, die auf einen Hadoop-Cluster verzichten.
Eine wichtige Frage bei der Speicherung von Daten ist neben der Geschwindigkeit und Menge auch die Lokation und die Verwendung von Cloud-Dienstleistern. Müssen oder sollen die Daten in einem lokalen Rechenzentrum, müssen oder sollen die Daten in Deutschland oder in Europa oder können und dürfen die Daten auch bei einem der erfolgreichen Cloud-Anbieter wie Amazon, Microsoft oder Google vorgehalten werden?
Compute
Nachdem wir die Frage der Speicherung geklärt haben, kommen wir zur Komponente Compute. Unter Compute verstehen wir die Bereitstellung von Rechenkapazitäten, beispielsweise zur aktiven Auswertung von Daten oder zur Ausführung bestimmter Vorhersagemodelle.
Ein Hadoop-Cluster vereint die beiden Komponenten, Storage und Compute. Nutzen wir zur Speicherung ein anderes, verteiltes Dateisystem, so sollten wir uns hier Gedanken machen, welche Rechenkapazitäten wir für die dritte Komponente, Analytics, benötigen.
Auch in verteilten Umgebungen gelten (aktuell) noch dieselben Gesetzmäßigkeiten wie bei Ihrem Laptop oder Desktop. Wir benötigen Arbeitsspeicher zum Einlesen von Daten. Bei vielen Nutzern benötigen wir mehr Speicher. Wir benötigen CPU-Kerne, damit wir die Daten verarbeiten können. Bei aufwändigen Kalkulationen, zum Beispiel bei der Bilderkennung, benötigen wir viele CPU-Kerne und müssen ggf. auf Grafikkarten zugreifen, die aufgrund ihrer Architektur viele Rechenoperationen parallel ausführen können. Bei vielen Anwendern benötigen wir viele Grafikkarten.
Dürfen die Daten in einer anderen Lokation ausgewertet als gespeichert werden? Im Falle von Amazon AWS scheinen aktuell zumindest die Kapazitäten in Ohio, USA, sehr viel umfangreicher und kostengünstiger verfügbar zu sein als in Frankfurt am Main im speziellen oder West-Europa im allgemeinen.
Ein weitere Trend ist in der Nutzung von Containern zu erkennen, die auf speziellen Systemen laufen, die die Ausführung dieser Container erlauben. Ein sehr einfacher Weg dieses zu erreichen ist die Nutzung eines eigenen Docker Hosts, auf welchem Systeme, Services oder Funktionen containerisiert laufen. Ein etwas aufwändigerer Weg ist der Aufbau eines Kubernetes Clusters, der die Verteilung der Container auf verschiedene Clustermember und den gleichzeitigen Start mehrere Container (Auto-Scaling) übernimmt. Wer den Aufbau oder die Wartung eines solchen Clusters scheut, kann bei den bekannten Cloud-Providern Kubernetes als (eingeschränkten) Platform-as-a-Service (PaaS) nutzen.
Analytics
Da wir das Thema Compute schon adressiert haben, haben wir somit den Punkt “wo führen wir die Analysen aus” bereits abgehandelt. Daher konzentrieren wir uns hier nun auf “wie führen wir die Analysen aus”.
Zu Beginn sollten wir das wie in zwei Bereiche unterteilen:
- organisatorisch
- technisch
Das organisatorische wie bezieht sich auf die Zusammenarbeit im Entwickler-/Analystenteam. Hier müssen folgende Fragen beantwortet werden:
- Arbeitet das Team mit agilen oder eher klassischen Methoden?
- Ist das Team in der Auswahl seiner Werkzeuge vollständig frei oder gibt es Rahmenbedingungen, die einzuhalten sind?
- Sollen Standardwerkzeuge für alle Teammitglieder bereitgestellt und mit Support unterstützt werden?
Das technische wie ist in einigen Punkte natürlich vom organisatorischen wie abhängig, denn wenn es keine Einschränkungen oder Vorgaben in der Verwendung der Werkzeuge gibt, kann man naturgemäß nur Empfehlungen aussprechen.
Nichtsdestotrotz ist es wichtig beim technischen wie zu überlegen, in welchem Umfang Frameworks und daraus folgende Blueprints genutzt und bereitgestellt werden. Hier möchte ich ein Beispiel nennen: Nehmen wir an, dass wir dem Entwickler-/Analystenteam keine Vorgaben in der Verwendung von Tools machen möchten. Dennoch soll neuen Mitarbeiter(inne)n und Kollegen aus anderen (Fach-)Bereichen der Einstieg in die Analysewelt einfach ermöglicht werden. Um beides zu erreichen müssen wir uns auf ein Basissetup einigen, auf welches die meisten Entwicklungen basieren und zu welchem wir Best Practices oder vielleicht sogar Seminare und (Online-)Trainings anbieten, da wir uns ansonsten in Einzel- und Besonderheiten verzetteln.
Dieses Basissetup muss nicht dem Gedanken der freien Toolauswahl wiedersprechen, da es nur bedeutet, dass wir für unsere tägliche Arbeit eine Rahmen festlegen und in besonderen Fällen dennoch alle Freiheiten erlauben.
Access
Mit der vierten Komponente, Access, adressieren wir Themen, die dem Bereich Data Governance zugeordnet sind. Und zwar
- Datensicherheit = Authentifizierung und Autorisierung
- Protokollierung
- etc.
Wie Sie der obigen Grafik entnehmen, ist Access ein Querschnittsthema (und Data Governance natürlich auch), da die zuvor genannten Punkte sich über alle drei vorherigen Komponenten erstrecken.
Das besondere bei der Komponenten Access ist der häufig formulierte Wunsch die gesamte Data Analytics Umgebung in das bestehende Berechtigungskonzept und -system des Unternehmens einzubinden, um beispielsweise Benutzer und Benutzergruppen nicht einzeln zu pflege oder beim Wechsel einer Mitarbeiterin von einer Abteilung in einer andere die notwendigen Berechtigungen nicht manuell nachführen zu müssen.
Eine hilfreiche Ergänzung zu dieser Komponente, und somit auch ein Querschnittsthema, ist die Dokumentation der Datenstrukturen, beispielsweise in einem Datenkatalog. Elemente der Datenstruktur sind neben der Beschreibung der Entitäten (=Tabellen) und Attribute (=Spalten) auch dessen Beschreibungen (was bedeutet die Spalte cdate?) und Ausprägungen (in der Spalte farbe kann grün, gelb und blau stehen). Der Datenkatalog hilft dem Anwender die für ihn richtigen Daten zu identifizieren, um dafür die entsprechenden Berechtigungen zu beantragen oder zugeordnet zu bekommen.
Fazit
Wie Sie sehen, kann man ein solch umfangreiches Thema wie Datenanalyse-Plattform in kleinere Bereiche zerteilen, womit das große Ganze seinen Schrecken verliert.
Hierbei handelt es sich aber nur um meine Einschätzung. Daher freue ich mich sehr auf Ihr Feedback und Ihre Erfahrungen.
Viele Grüße, Oliver Rothland